虽然mongodb作为一个款明星级的NoSql数据库,但是它的磁盘回收却让很多人较为头痛。
说明
- 下面的方案只适用于replica sets模式的mongodb集群。
- 我们线上的mongodb版本为2.0.0,但是也适合于其他的版本。
自动同步方案
依赖于mongodb的同步方案,即不采用fastsync方式。这种方案比较简单,但是只能针对数据量和新增数据量不多的情况。因为如果你的数据量太大而新增数据又太多,可能就会出现同步时间太长,而oplog已经把你还没有同步的日志给覆盖了,从而导致集群数据不一致的情况。具体操作步骤如下:
1 | 1.首先在primary将需要整理的secondary下线:rs.remove(“172.16.1.153:10000”)。 |
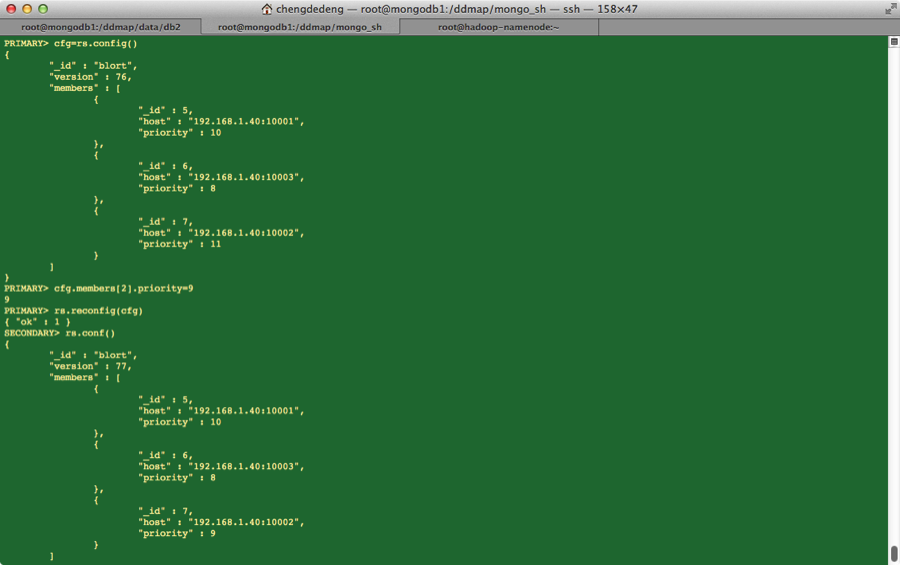
特别说明
- 检查数据是否跟主节点一致非常重要,因为如果数据不一致,肯定会造成数据丢失情况。
- 降级操作图见下图:
RepairDatabase方案
由于repairDatabase命令,会锁住整个库,并且在2.0.0不能运行在secondary节点,但是在2.6之后就可以在secondary节点运行了。
1 | 1. 先将secondary节点下线 |
1 | 1. RepairDatabase和自动同步方案的效率,我没有比较过,并且我在线都使用的是自动同步方案,不是因为第二种方案不好,因为我刚开始就选择了该方案,并且没有出过问题,为了线上数据的安全,因此一直采用此种方案。 |